Foreword
The Speech Corpus of the Spanish/Portuguese Border (FRONTESPO-COR) is a work that is constantly being updated. Its core consists of almost 300 hours of recordings, most of which are on video, the result of interviews with 287 informants from different age groups carried out in 64 towns on both sides of the border between 2015 and 2017. Of these recordings, a small sample is currently available to the public; this amount will increase progressively over the coming months. If any researcher, teacher, community member, etc. is interested in the materials that have not been uploaded yet, please contact us at frontespo@gmail.com
Furthermore, we are working on digitalizing and editing other primary materials from the border region. We would greatly appreciate receiving any unedited recordings (linguistic surveys, ethnographic research, family recordings, etc.) for their open publication according to our usage license; please write to us at frontespo@gmail.com. Thank you for your collaboration.
Forma de cita
Álvarez Pérez, Xosé Afonso (dir.) (2018 - ): Corpus oral de la frontera hispano-portuguesa, Alcalá de Henares: FRONTESPO. <http://www.frontespo.org/en/corpus> [Consulted on: <date>]. ISSN 2605-0471.
Organisation of the Corpus
To facilitate consultation and management of the corpus, each interview has been segmented into several recordingscentred on different topics — normally, between six and eight sessions, which each last between 10 and 20 minutes on average — which are presented independently in the FRONTESPO-COR.
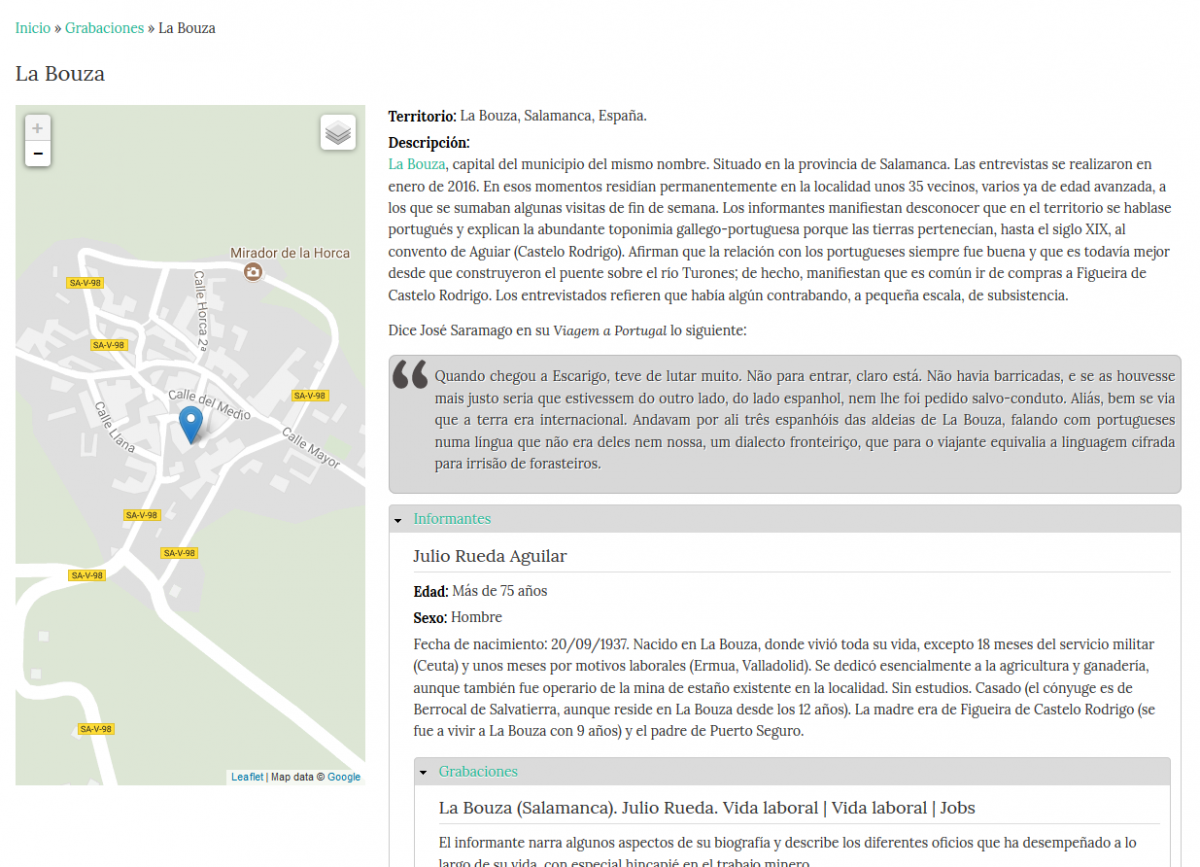
The recording entry is the main means (but not the only means) of accessing all of the corpus information. The main screen of the FRONTESPO-COR displays an abbreviated version that links to three elements:
- Geographic location entry.
- Informant entry.
- Multimedia files.
By clicking on the recording title, you can access the full entry, which offers several additional elements:
- Description of the content (in Spanish, Portuguese and English).
- Topical classification.
- Multimedia field, where you can watch the recordings directly on our page, or you can open the repositories in SoundCloud, Vimeo and YouTube.
- Transcription of the content, both aligned with the audio and video (ELAN) and in text (PDF and TXT).
The geographic location entry can be accessed from the recording entry or from the map located to the left of the main window. This entry contains;
a) a map with the town's location
b) the delimitation of the administrative territory to which it belongs (local government, province/district)
c) a brief description of the main geographic and historic characteristics of the town, with links to other sources of information, when appropriate
d) a list of the informants interviewed in each location and the recordings in which each participates, with the option of directly consulting the recordings and transcriptions.
The informant entry provides the individuals’ names (except when they request to remain anonymous), their sex and age group, as well as a brief description of their sociolinguistic profile: place and date of birth, profession, education, travel outside of the town, as well as other circumstances that may be relevant for analysing the interviews. As with the above cases, the recordings can be accessed directly from this entry.